
Technologies
Artificial Intelligences
March 2022
Artificial intelligence (AI) is a driving force for the development of innovative medical products. Applying big data approaches is not particularly promising due to the limited size of typical medical data sets. Nevertheless, medical applications with limited data sets can become success stories if the right techniques are applied. Helbling has the experience, know-how, and tools to make this a success.
More and more of Helbling’s clients, especially from the medical sector, find that obtaining large amounts of data is expensive and time-consuming. Reasons for the difficulties are the duration and costs of clinical studies, including approval by an ethics committee, required expensive equipment, and data annotation experts. These reasons also prevent some small and medium-sized companies from integrating AI into their products. Helbling has successfully applied techniques that enable the use of powerful AI in the medical field despite the challenge of limited data sets. The techniques presented in the following sections improve the performance of AI models significantly for limited data set applications and are illustrated with projects in which Helbling has been involved. Due to confidentiality reasons, illustrations are based on publicly available sources.
Technique 1: Reducing model complexity to lower the amount of data required
The amount of data needed for training correlates with the model complexity represented by the number of model parameters. The number of parameters can be reduced by limiting the scope of the model or using extracted features instead of raw data.
Technique 2: Data augmentation to increase data amount and variability
Data augmentation refers to artificially increasing the amount and variability of data. This technique adds slightly modified copies of existing data or creates new synthetic data. Applicable methods for data augmentation are selected based on domain knowledge. Data augmentation is explained below with a project for the image-based diagnosis of skin cancer in which Helbling was involved as a development partner.
To increase image variability and the accuracy of image classification, three types of image transformations are helpful. Firstly, image transformations are used to introduce imaging variations, e.g., by adding image noise, reducing image contrast, changing the ambient light level, or homogeneity of illumination. Secondly, image transformations are employed to add user-induced variability. This involves motion blurs and various device alignments. Thirdly, the properties of the object are changed. In the example of skin cancer diagnosis, hairs can be added, or the skin color is changed.
The combination of the presented image transformations increases the variability further. It is important that the image transformations do not alter the object class (e.g., malignant or benign mole); only the appearance should change.

Technique 3: Transfer learning to benefit from other data sources and/or similar problems
Transfer learning refers to the process of applying knowledge from a solved problem to a new problem. For transfer learning to be effective, the two problems must be related.
One form of transfer learning is to use pre-trained layers of a well-established neural network and retrain a subset of layers for a new task. An example of a publicly available and widely used neural network is AlexNet [2], which is a convolutional neural network containing eight layers that have been trained on 14 million pictures.
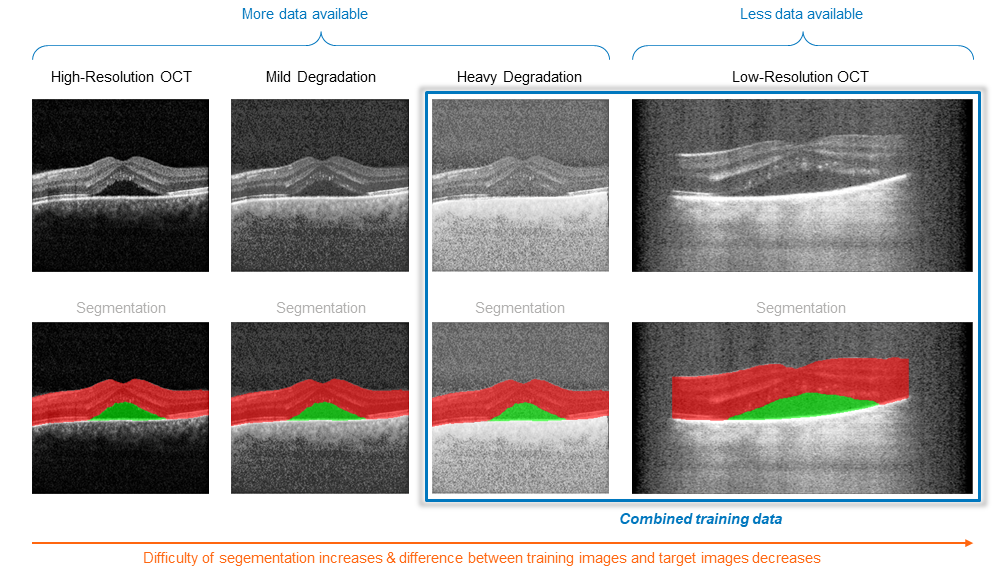
Another form of transfer learning is the combination of a small available data set with data acquired by another device. This technique is also referred to as domain adaptation. Helbling applied transfer learning to a project in the field of ophthalmology. As illustrated in Figure 2, high-resolution images acquired with a commercial instrument were artificially degraded to look like the images acquired with the product under development. The degraded images are used to increase the database and the diversity of the training set.
Specialty: Handling unbalanced data sets
In an unbalanced data set, most data points belong to one class while other classes are underrepresented; for example, in quality control only a few parts show a defect. Unbalanced data sets make learning the underrepresented classes difficult, which are the classes of interest in many applications.
Option one is to synthetically create new data points for the underrepresented class, such as by synthetic minority oversampling (SMOTE) [5]. SMOTE artificially creates new data points by interpolating between two or more existing data points. This technique works well with scalar data and is less appropriate for image data.
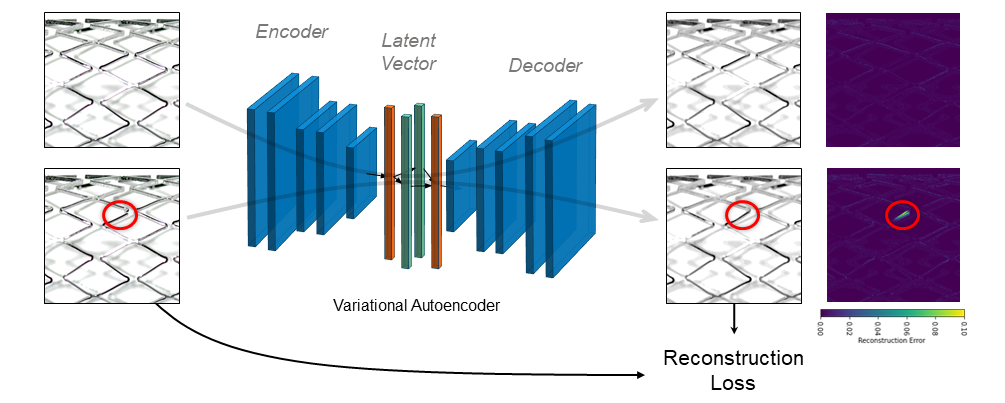
Option two for binary classification is to only use data points of the majority class and train a neural network to detect deviations from the majority class. The figure below illustrates the working principle of a variational autoencoder [6] for detecting stent defects.
Specialty: Changing measurement technology during development
To minimize time to market and assess achievable performance early, the measurement technology and AI model must be developed in parallel as they are interdependent. Various data sources are used during development. In the past, Helbling has used publicly available data based on similar measurement technologies or simulated data until the measurement technology was developed. It is also possible to work with data from existing products based on identical or similar measurement technologies. Finally, data obtained from various development prototypes is used in the development of AI models. An important aspect is that the evaluation of intermediate AI models also influences the development of the measurement technology, such as required data resolution or image stabilization (acceptable movement blur).
Summary: Helbling facilitates AI with limited data sets through in-depth specialist knowledge
Domain knowledge – this includes medical expertise and understanding of both physical processes and user interaction – is a key factor for successfully applying the presented techniques to develop AI models with limited data sets. Based on the domain knowledge, model complexity can be reduced, data amount and variability can be artificially increased, and transfer learning can be applied. In addition, efficient development handles unbalanced data sets and develops the AI model in parallel with measurement technology to meet challenging time-to-market goals. Helbling is developing AI applications by taking full advantage of internal and external knowledge networks.
Autoren: Matthias Pfister, Urs Anliker, Cyril Stoller, Simon Kurmann
Main image: metamorworks via istockphoto
Authors: Matthias Pfister, Urs Anliker, Cyril Stoller, Simon Kurmann
References
[1] International Skin Imaging Collaboration (“ISIC”), www.isic-archive.com
[2] Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton (2017-05-24). “ImageNet classification with deep convolutional neural networks”. Communications of the ACM. 60 (6): 84–90. doi:10.1145/3065386. ISSN 0001-0782. S2CID 195908774
[3] von der Burchard, Claus, et al., Self-examination low-cost full-field OCT (SELFF-OCT) for patients with various macular diseases., 2021
[4] https://creativecommons.org/licenses/by/4.0/, February 2, 2022
[5] N.V. Chawla et al., SMOTE: Synthetic Minority Over-sampling Technique, Journal Of Artificial Intelligence Research, Volume 16, pages 321-357, 2002
[6] D.P. Kingma et al., Auto-Encoding Variational Bayes, arXiv preprint arXiv:1312.6114, 2013




