
Industries
Technologies
Artificial Intelligences
Over the last five years, neuromorphic computing has rapidly advanced through the development of state-of-the-art hardware and software technologies that mimic the information processing dynamics of animal brains. This development provides ultra-low power computation capabilities, especially for edge computing devices. Helbling experts have recently built up extensive interdisciplinary knowledge in this field in a project with partner Abacus neo. The focus was also on how the potential of neuromorphic computing can be optimally utilized.
Similar to the natural neural networks found in animal brains, neuromorphic computing uses compute-in-memory, sparse spike data encoding, or both together to provide higher energy efficiencies and lower computational latencies versus traditional digital neural networks. This makes neuromorphic computing ideal for ultra-low power edge applications, especially those where energy harvesting can provide autonomous always-on devices for environmental monitoring, medical implants, or wearables.
Currently, the adoption of neuromorphic computing is restricted by the maturity of the available hardware and software frameworks, the limited number of suppliers, and competition from the ongoing development of traditional digital devices. Another factor is resistance from conservative communities due to their limited experience of the theory behind and practical use of neuromorphic devices, with the need for a new mindset to approach problems relating to both hardware and software.
Given the inherent relative benefits of neuromorphic computing, it will be a key technology for future low-power edge applications. Accordingly, Helbling has been actively investigating currently available solutions to assess their suitability for a broad range of existing and new applications. Helbling also cooperates with partners here, such as in an ongoing project with Abacus neo, a company that focuses on developing innovative ideas into new business models.
The von Neumann bottleneck needs to be overcome
The main disadvantage of current computer architectures, both in terms of energy consumption and speed, is the need to transfer data and instructions between the memory and the central processing unit (CPU) during each fetch-execute cycle. In von Neumann devices, the increased length and thus electrical resistance of these communication paths leads to greater energy dissipation as heat. In fact, often more energy is used for transferring the data than for processing it by the CPU. Furthermore, since the data transfer rate between the CPU and memory is lower than the processing rate of the CPU, the CPU must constantly wait for data, thus limiting the system’s processing rate. In the future, this von Neumann bottleneck will become more restrictive as CPU and memory speeds continue to increase faster than the data transfer rate between them.
Neuromorphic computing collocates processing and memory
Neuromorphic computing aims to remove the von Neumann bottleneck and minimize heat dissipation by eliminating the distance between data and the CPU. These non-von Neumann compute-in-memory (CIM) architectures collocate processing and memory to provide ultra-low power and massively parallel data processing capabilities. Practically, this has been achieved through the development of programmable crossbar arrays (CBA), which are effectively dot-product engines that are highly optimized for the vector-matrix multiplication (VMM) operations that are the fundamental building blocks of most classical and deep learning algorithms. These crossbars comprise input word and output bit lines, where the junctions between them have programmable conductance values that can be set to carry out specific algorithmic tasks.
Therefore, for a neuromorphic computer the algorithm is defined by the architecture of the system rather than by the sequential execution of instructions by a CPU. For example, to perform a VMM, voltages (U) representing the vector are applied to the input word lines whilst the matrix is represented by the conductance values (G) of the crossbar junction grid. The result of the VMM is then given by the currents (I) flowing from the output bit lines (see Figure 1). Since a VMM operation is performed instantaneously in a clockless, asynchronous manner, the latencies and processing times are much lower than for traditional von Neumann systems.
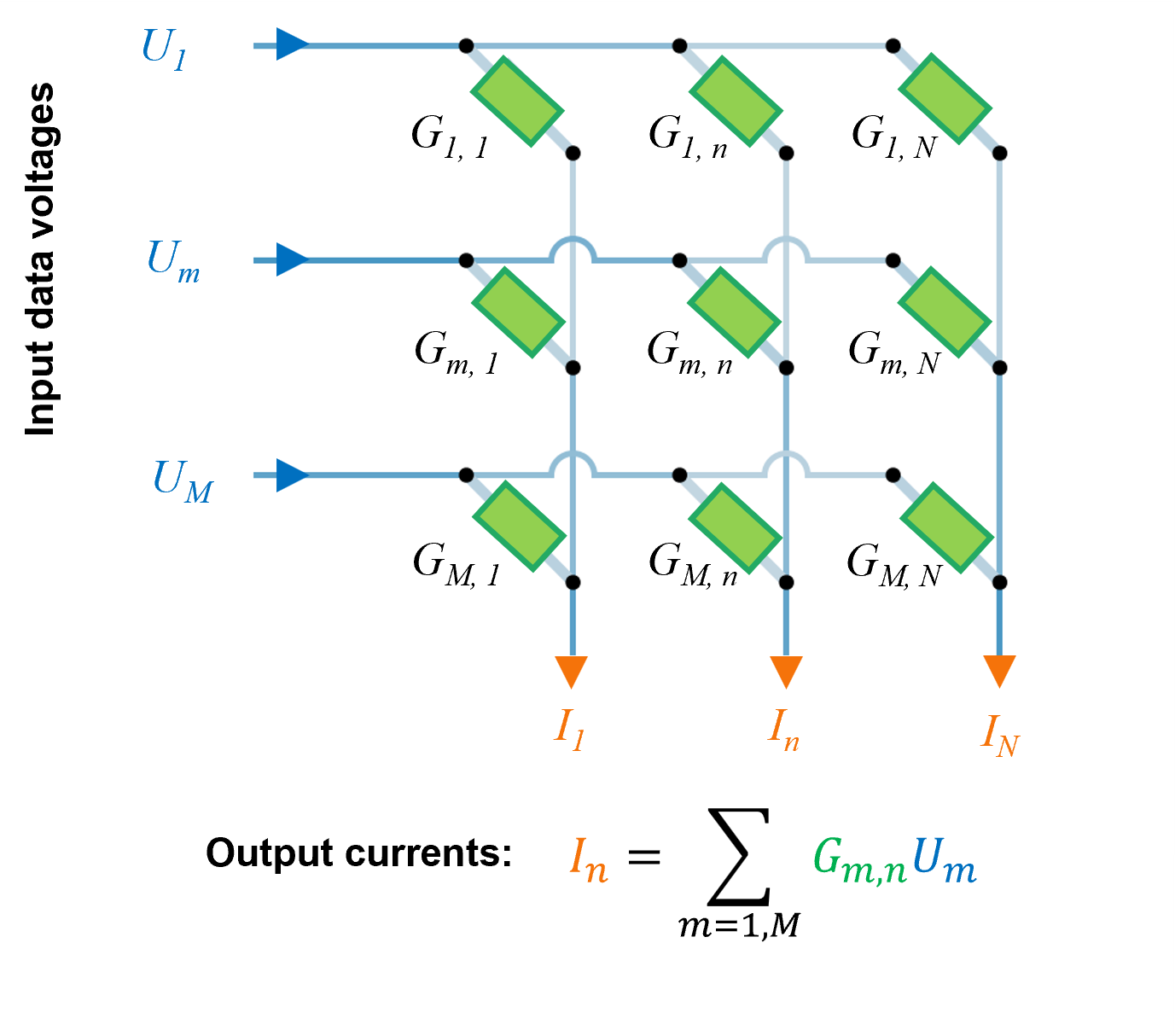
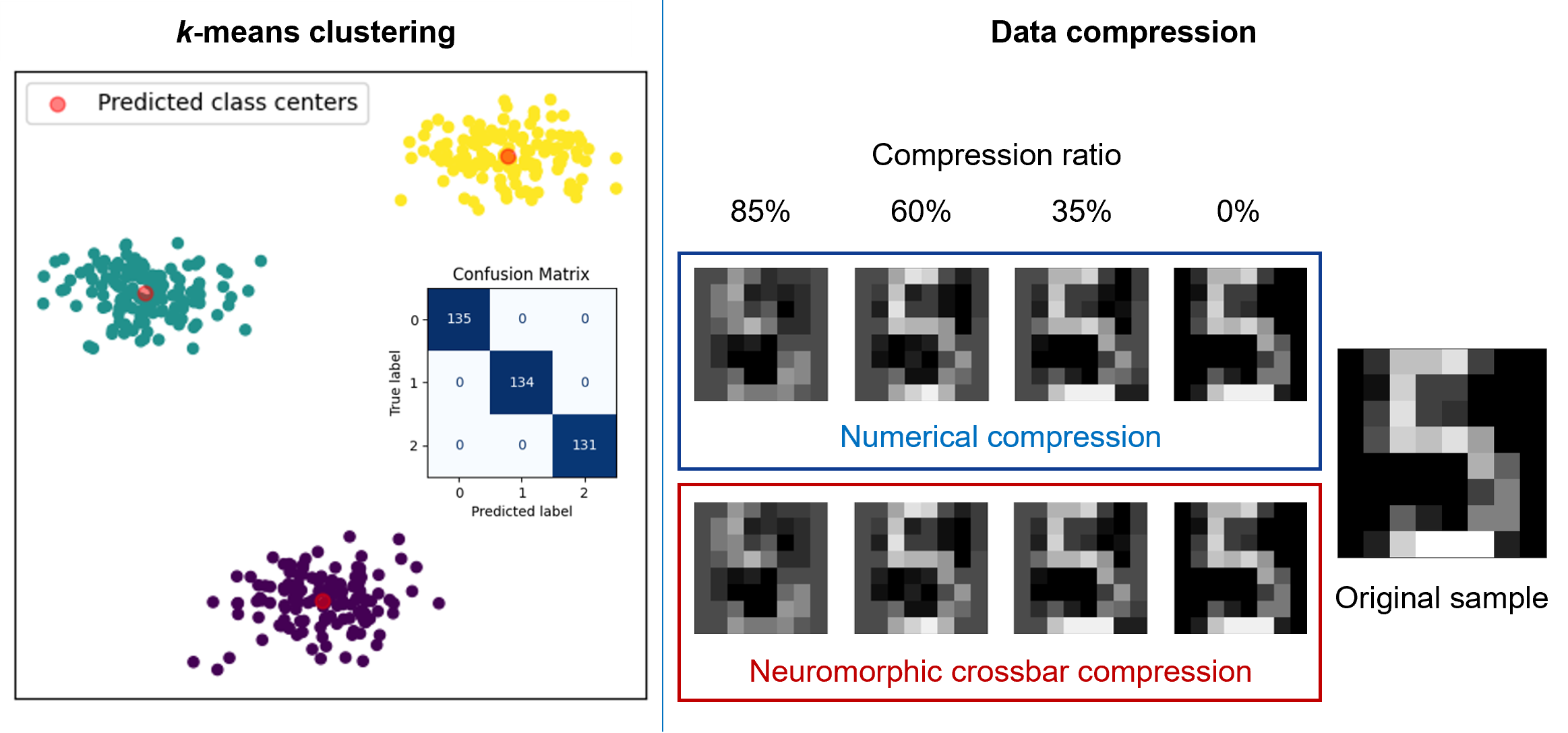
The energy cost of implementing a VMM on a CBA is very low versus that of a von Neumann device since energy is only required to impose the input word line voltages and to overcome the electrical resistance losses of the CBA.
Sparse data representation reduces energy requirements
The second main feature of neuromorphic computing is its time-dynamic nature and the flow of sparse event encoded data through spiking neural networks (SNN).
Event encoding typically involves converting a continuous signal into a train of representative short-duration analog spikes. Techniques include rate encoding, where the spike frequency is proportional to the instantaneous signal amplitude, or time-encoded spikes that are generated when a signal satisfies pre-defined thresholds. The advantages of this sparse representation are the very low power required for transmission and the ability to develop asynchronous, event-driven systems.
Leaky integrate-and-fire (LIF) neurons implemented at the hardware level form the basis of the SNN used in neuromorphic computing. The operation of these LIF neurons is shown in Figure 3. Essentially, the spikes entering a neuron are multiplied by the pretrained weight (w) of their respective channels. These are then integrated and added to a bias value, before being added to the instantaneous membrane potential (VM) of that neuron. This membrane potential leaks with time as it decreases at a programmable rate, thus providing the neuron with a memory of previous spiking events. If the membrane potential is greater than a predefined threshold (VTH), the neuron fires a spike downstream before resetting to its base state to create a continuous time dynamic process.
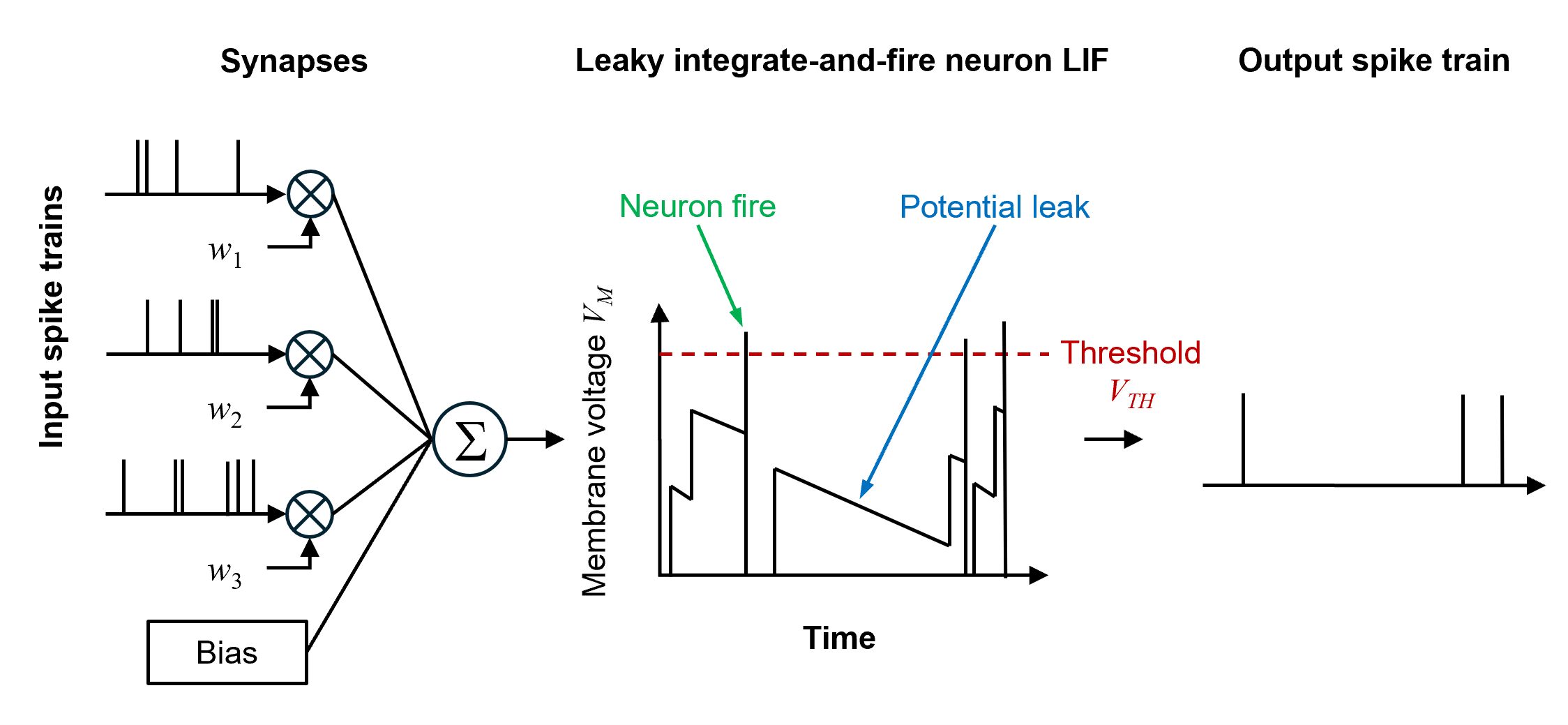
Neuromorphic elements need to be integrated into devices
In a practical neuromorphic device, the CBA is integrated into a neuromorphic processing unit (NPU) with pre- and post-signal conditioners to encode the input spikes and decode the output spikes, respectively (see Figure 4). Since the nature of these signal conditioners greatly affects the overall performance of the system and can eliminate any energy or latency benefits gained from the use of a neuromorphic computation core, their choice is critical to the overall comparative effectiveness of a neuromorphic solution. For example, the energy consumption and latency of typical microcontrollers are much higher than for a CBA, thus limiting their suitability. Ideally, input spike generation should be purely analog or performed on the sensors before application to the input word lines of the CBA. An interesting solution is the implementation of sensor fusion during pre-conditioning to reduce the dimensionality of the combined multi-sensor inputs, thus only processing features of relevance to the application. This is particularly beneficial when the number of input word lines of the CBA is limited.
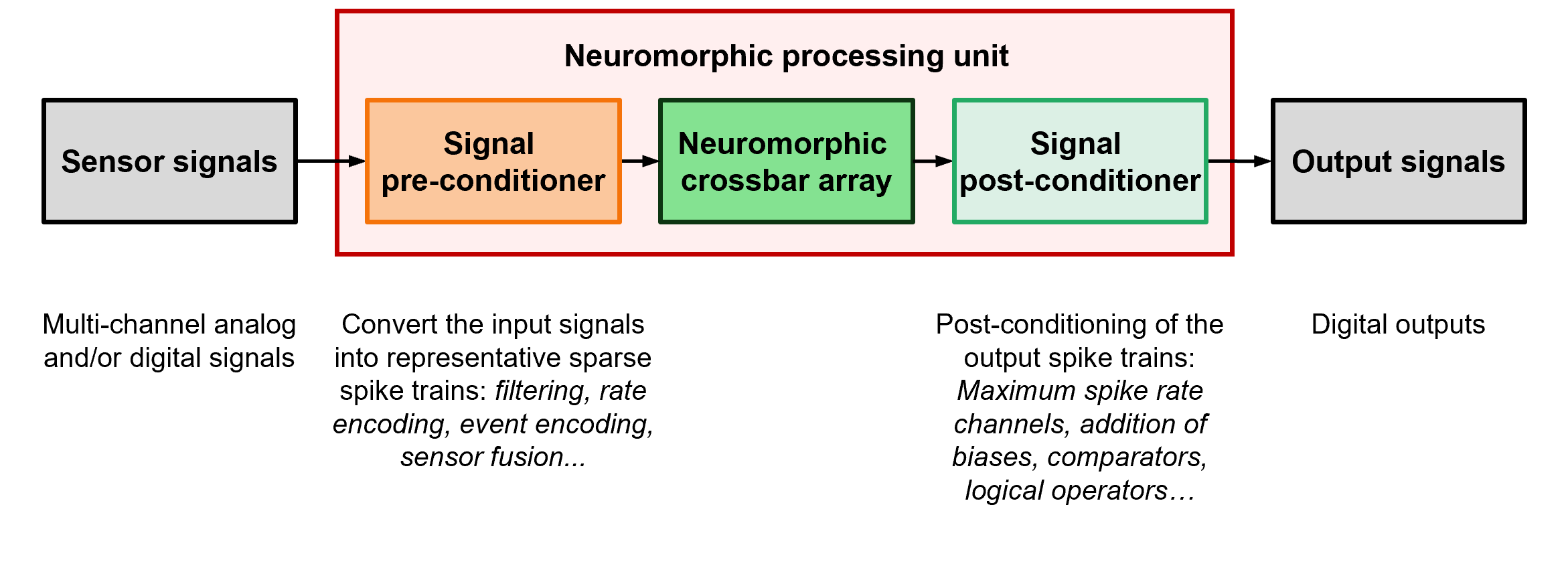
Summary: Neuromorphic computing has untapped potential for future technologies
Due to its inherent features, neuromorphic computing provides enormous advantages versus traditional digital electronic devices with von Neumann architectures. Benefits include very low computation latencies and ultra-low energy requirements. However, due to the need for a new engineering mindset to approach problems and a lack of community knowledge of the relevant technologies, the full potential of neuromorphic computing has yet to be leveraged. As such, Helbling experts from various disciplines have studied the topic intensively and believe that it will be a decisive factor in future MedTech and system monitoring applications. With this expertise and the intensive partnership with Abacus neo, Helbling is positioning itself as an important industry partner and trailblazer.
Authors: Navid Borhani, Matthias Pfister
Main Image: Copilot



